All figures are original and the source code is available at https://github.com/jayneel-p.
Introduction
A substantial portion of the computational resources deployed in financial markets is spent on pricing and risk management [1]. Financial derivatives are contracts whose payoff depends on the future price or trajectory of an underlying asset. Their prices require expectations under stochastic models, and only for simplest contracts do these expectations have a closed form. The Black—Scholes—Merton model [2, 3] prices vanilla European options analytically, but once the payoff depends on the path of the asset, or on several correlated assets, or if the underlying assumptions for the BS model fail (constant volatility, log-normal distribution, constant risk-free interest, perfect liquidity), the standard tool becomes Monte Carlo simulation [4].
Monte Carlo handles arbitrary payoff structures and stochastic dynamics with little change to the method. Its cost is statistical: with independent paths the standard error decays as , so halving the error demands four times the computation. This rate is a fundamental consequence of the central limit theorem, and it has motivated a long line of classical work aimed at reducing the variance of the estimator without changing the convergence exponent. Kemna and Vorst [5] observed that for arithmetic Asian options, whose payoff depends on the time-average of the underlying, the geometric-average Asian has a closed form and is highly correlated with the arithmetic payoff. Using it as a control variate removes most of the sampling noise. At daily monitoring frequency the standard error drops by a factor of roughly , comparable to the range reported in the literature for similar regimes [4, 5]. A quantum method for this contract should be compared with that reduced-variance scale, not only with simple Monte Carlo.
Quantum amplitude estimation [6] tackles the same expectation-estimation problem from a different direction. Given a unitary operator that prepares the probability distribution and encodes the payoff into an amplitude, amplitude estimation recovers the expectation with oracle queries for additive error , a quadratic improvement over the classical sampling rate. Rebentrost, Gupt, and Bromley [1] formulated this pricing map under the Black—Scholes model. Stamatopoulos et al. [7] made the construction explicit at the circuit level, including comparators, payoff rotations, weighted sums for basket and path-dependent options, and small IBM-hardware demonstrations. Their reported full amplitude-estimation circuits for European examples already range from depth at sampling qubits to depth at , before considering daily path dependence. Wang and Kan [8] push the resource question further for Asian and barrier options under stochastic volatility: even their more efficient weak-Euler instances have -counts of order and require — logical qubits. Manzano et al. [9] study an alternative encoding pipeline, while Rendon et al. [10] pursue a PDE-based route that changes the bottleneck rather than improving the same Monte Carlo estimator.
The QAE speedup should be read as a query-model statement. It counts calls to the pricing oracle, not the cost of building that oracle. Each oracle call is itself a quantum circuit whose depth grows with the number of qubits used to discretize the price distribution, the complexity of the payoff function, and the number of time steps in the path. The classical baseline changes with the estimator. For path-dependent and high-dimensional contracts, variance reduction can lower the effective cost of Monte Carlo by orders of magnitude. Many existing quantum pricing papers benchmark against simple Monte Carlo, which can overstate the practical gap.
This paper separates three questions. First, how much does the Kemna—Vorst control variate change the Asian Monte Carlo baseline? Second, does the implemented European circuit encode the intended payoff expectation? Third, how quickly does path dependence enter the oracle cost? The answer is unfavorable to simple quantum-advantage narratives: the query speedup remains, but the classical baseline and the oracle are both stronger than the headline comparison suggests.
Financial background
Risk-neutral geometric Brownian motion
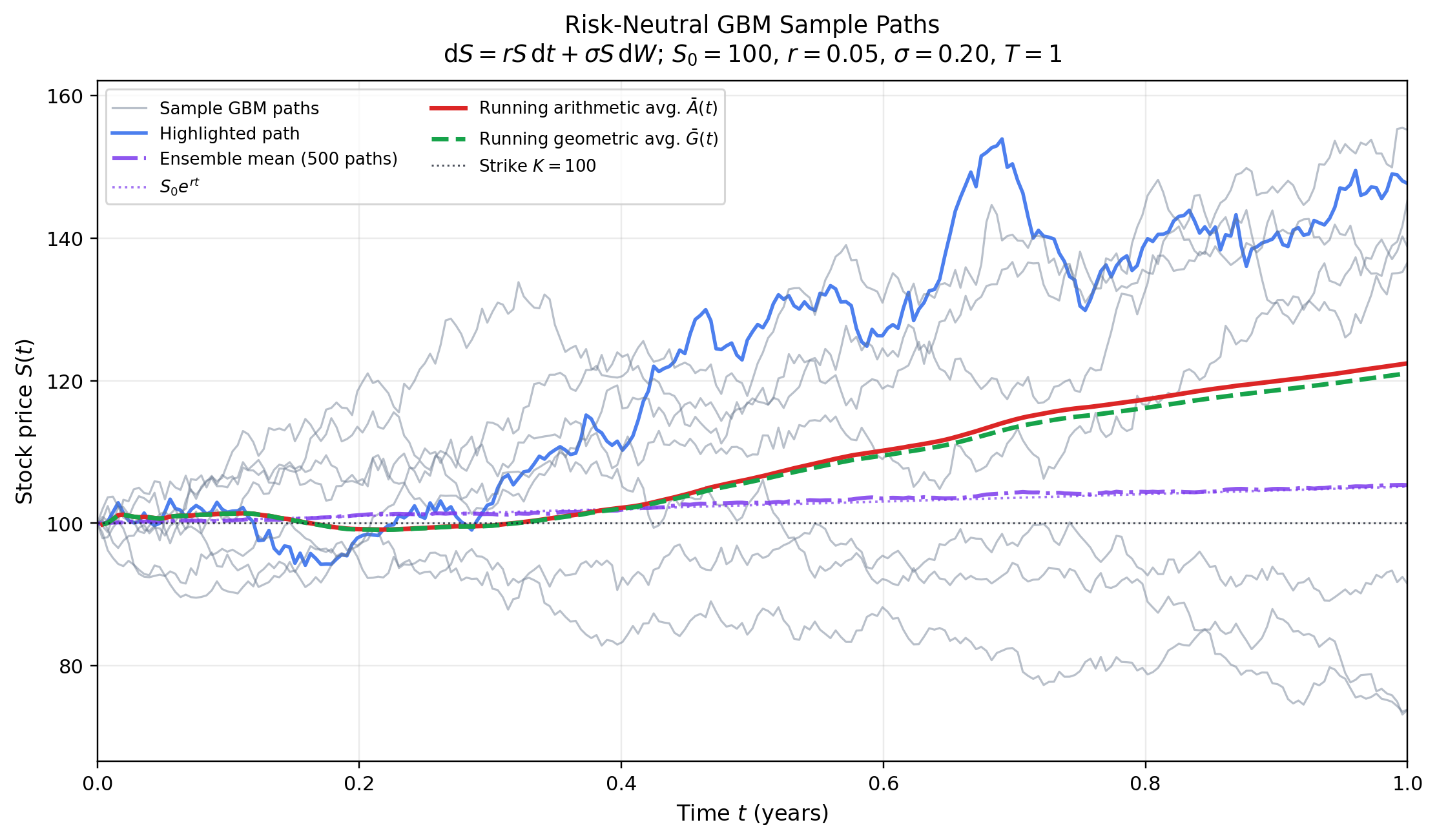
Let be the price of one risky asset at time . In the Black—Scholes model the physical-market dynamics are written
where is the physical drift, is the volatility, and is a Brownian motion. Pricing is performed under a risk-neutral measure , where the drift is the risk-free rate . The pricing dynamics are
Here is Brownian motion under . This is the model used in the simulations below and in the standard quantum-pricing setup [1, 7].
For initial asset price and maturity time , Eq. [eq:risk-neutral-gbm] gives
where is a standard normal random variable. Thus is lognormal.
If is the payoff paid at time , the time-zero price is
Here is the option value at time zero and is the discount factor.
European calls
A European call with strike has payoff
Here denotes the European-call payoff and is the terminal asset price. Under Eq. [eq:risk-neutral-gbm], its Black—Scholes price is
where is the Black—Scholes call price, is the standard normal cumulative distribution function, and
The quantities and are the normalized log-moneyness terms. This closed form is used as a benchmark.
Arithmetic Asian calls
Let be monitoring dates satisfying
The arithmetic Asian call depends on the average of the asset prices at these dates. The dates are taken equally spaced and is not included. The arithmetic average is
where is the average over the monitored prices. The payoff is
Here denotes the arithmetic Asian payoff. The arithmetic average of lognormal random variables is not lognormal, so Eq. [eq:arith-asian-payoff] has no Black—Scholes-type closed form in this model.
The corresponding geometric average is
Here is the geometric average over the same monitoring dates. Since the log-prices are jointly normal, is normal. The geometric Asian call therefore has a closed-form price and is highly correlated with the arithmetic Asian call. Kemna and Vorst use this structure as a control variate [5].
For equally spaced fixings excluding , define the effective geometric volatility and drift parameter by
Then the logarithm of the geometric average is distributed as
The resulting geometric Asian call price is
where is the geometric Asian call price and
The variables and are the analogues of and for the distribution of .
Classical Monte Carlo baseline
Simple Monte Carlo
Let be the discounted payoff
where is the payoff at maturity. If are independent samples of , the simple Monte Carlo estimator is
where is the estimated time-zero price. The estimator is unbiased under the risk-neutral model. Its standard error is
where is the payoff variance. In computation this is estimated by replacing with the sample variance. The dependence is the classical Monte Carlo rate [7, 11].
For the European call, samples are drawn directly from Eq. [eq:gbm-solution]. For the arithmetic Asian call, paths are simulated on the monitoring grid. With time step , the exact geometric Brownian transition is
Here and are consecutive monitored prices and is a standard normal draw. The grid values are therefore sampled without time-discretization bias.
The numerical experiments use the parameter set
For the Asian option, daily monitoring dates are used. The European Black—Scholes benchmark is
The geometric Asian benchmark is
Kemna—Vorst control variate
Simple Monte Carlo is not the strongest classical baseline for Asian options. Let
be the discounted arithmetic payoff and let
be the discounted geometric payoff. Here is the target payoff and is the control payoff. The expectation is known from Eq. [eq:geo-asian-price]. A control-variate estimator is
where and are sample averages over the same simulated paths and
The quantity estimates the variance-minimizing coefficient . The estimator remains centered on the arithmetic Asian price but removes the part of the arithmetic payoff fluctuation explained by the geometric payoff.
For paths and fixings, the plain estimator has standard error . The Kemna—Vorst estimator has standard error . This is a standard-error reduction of and a variance reduction of . In this parameter regime, control-variate paths have about the same variance as simple Monte Carlo paths.
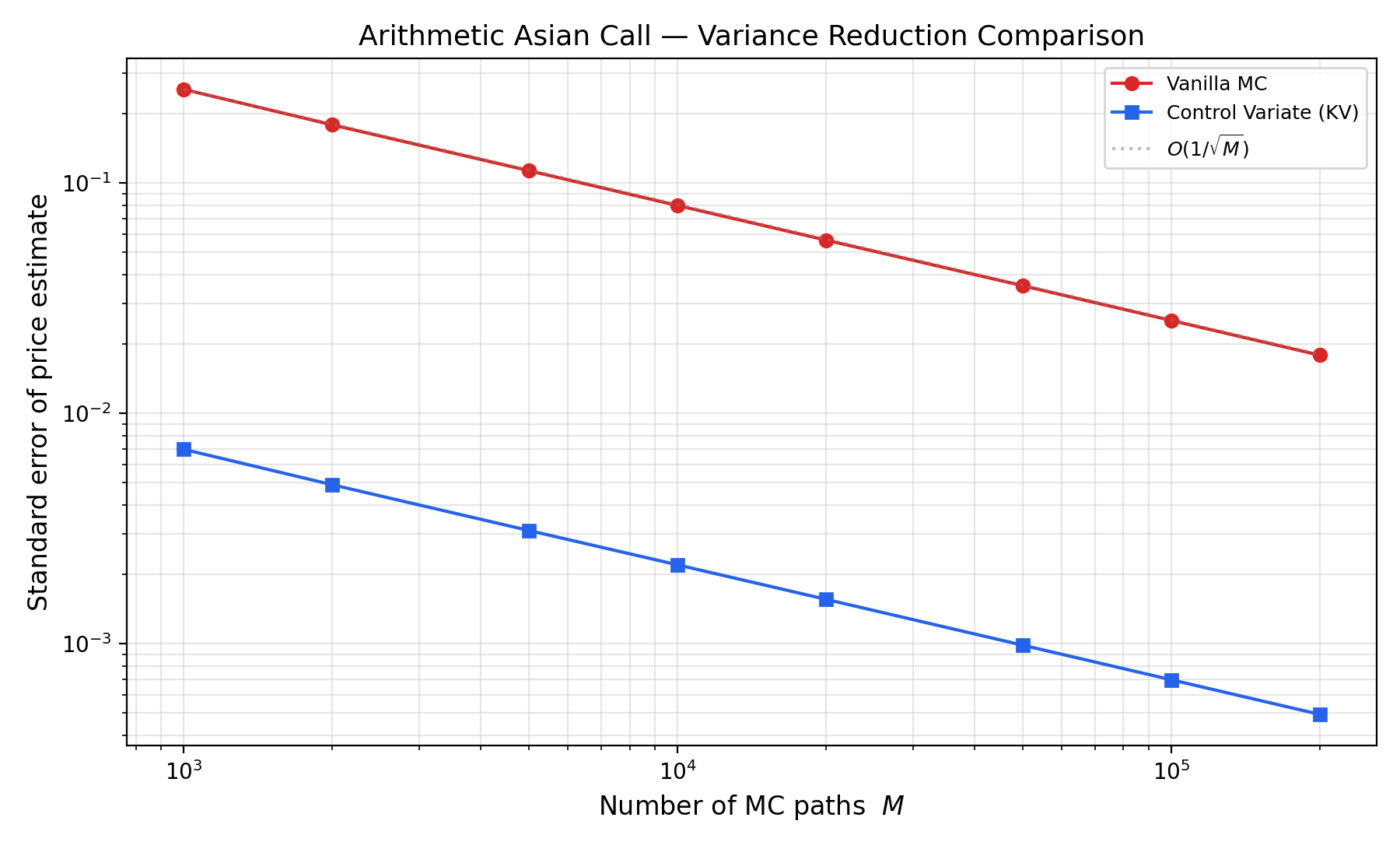
The control variate leaves the rate in place, but it lowers the constant by a large factor. This is the baseline used below.
Quantum amplitude estimation framework
Encoding an expectation as an amplitude
The quantum approach does not sample payoffs. Instead it encodes the undiscounted payoff expectation as the probability of measuring a single qubit in the state . Discounting by is applied classically afterward, exactly as in Eq. [eq:risk-neutral-price].
Discretize the terminal asset price onto grid points with probabilities . A distribution-loading unitary prepares the state
where is the -qubit computational basis state representing . The amplitudes are square roots of probabilities, so that the Born rule returns upon measurement of basis state . The price register, any ancillas, and the objective qubit are part of one joint quantum state. Payoff operations may entangle these registers, but the full map remains unitary until the final measurement.
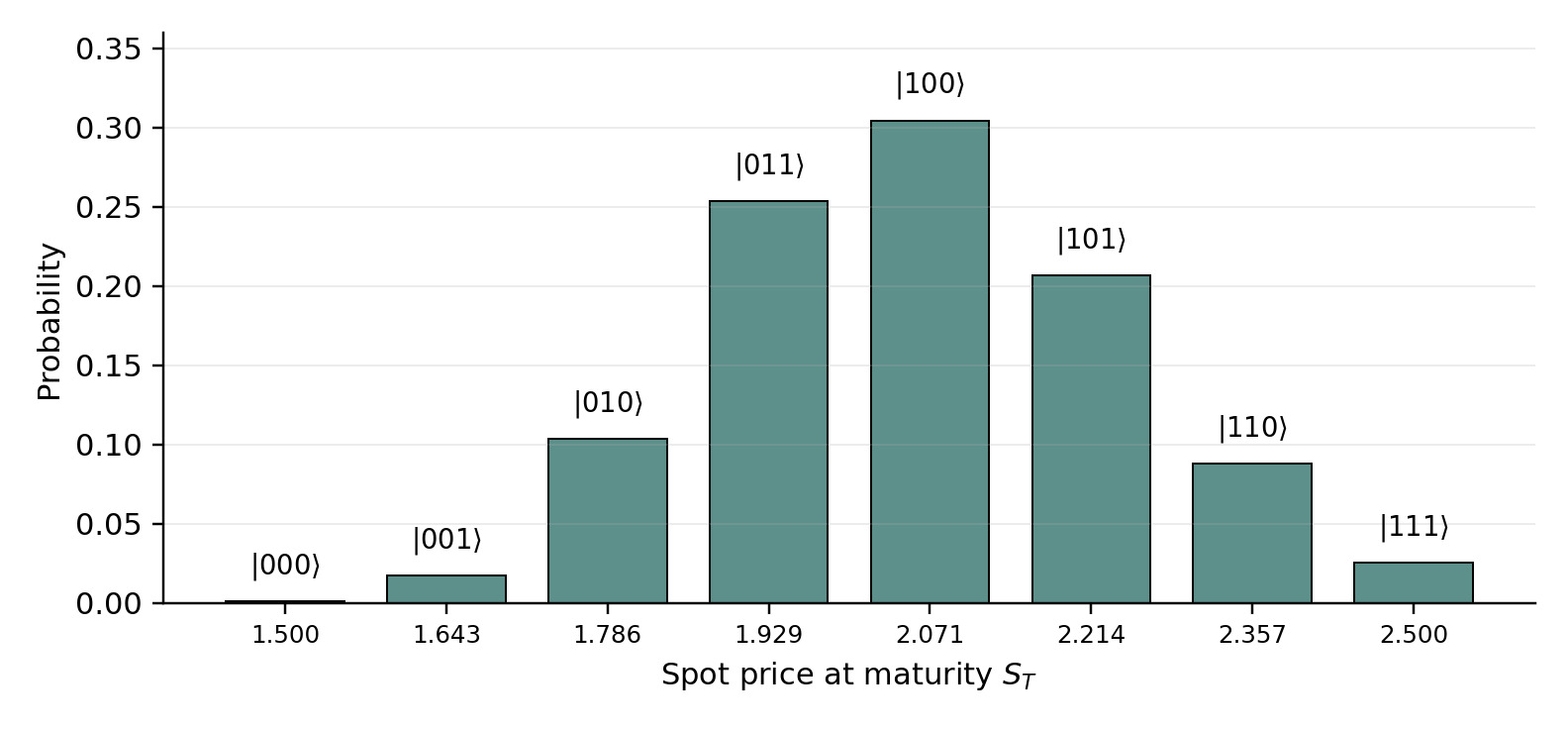
Let be the payoff at grid point , and let bound it from above so that the normalized payoff satisfies . A payoff unitary rotates one objective qubit conditioned on the price register:
The full state-preparation operator acts on qubits. Applying it to the all-zero input gives
where collects all terms with objective qubit and collects those with . The Born rule now does the work. The probability of measuring the objective qubit in state is the sum of the squared amplitudes in the subspace, which by construction equals
Thus the measurement probability is exactly the normalized expected payoff. The operator follows the prepare-then-compute pattern common to quantum algorithms. Here prepares the input distribution, computes the function of interest into an ancilla amplitude, and measurement extracts the expectation [1, 7].
For a European call, and the time-zero price is
Stamatopoulos et al. implement with controlled rotations and a first-order approximation to the payoff map [7]. The implementation used here keeps the same division between distribution loading and payoff rotation.
Amplitude amplification and estimation
Estimating by repeated measurement of would reproduce the Monte Carlo rate. The quadratic improvement comes from amplitude estimation, which repeatedly applies the Grover iterate defined below [6]. In Grover search the goal is to find a marked item; here the “marked” states are those where the option finishes in the money, and the goal is to estimate their total weight.
Define the projector onto the subspace where the objective qubit is , and the two reflections
The Grover iterate is
The reflection marks the good subspace; reflects about the prepared state. Two reflections compose into a rotation in the two-dimensional subspace spanned by and . Writing with , repeated applications give
Hence each application of advances the state by angle toward the good subspace. Amplitude estimation recovers , and hence , by applying phase estimation to [6]. With oracle calls the error scales as , the quadratic improvement over sampling.
The numerical experiments use iterative amplitude estimation (IAE), which avoids the inverse quantum Fourier transform and controlled- powers of the circuit. IAE estimates the same angle through a sequence of Grover iterates at different depths, combined with classical likelihood inference [7, 12]. At each depth , the measured success probability is , so the classical post-processing updates an interval for rather than reading it from a phase-estimation register. Only the estimation subroutine differs from canonical QAE; the state preparation in Eqs. [eq:distribution-loading]—[eq:amplitude-expectation] is unchanged.
European-call circuit
The operator for a European call has two stages: load the terminal price distribution and rotate the objective qubit according to the normalized payoff. Fig. 4 shows the high-level structure. In practice, is estimated by IAE rather than by naive Bernoulli sampling of the objective qubit; the classical rescaling in Eq. [eq:european-amplitude-price] then recovers the option price [7, 12].
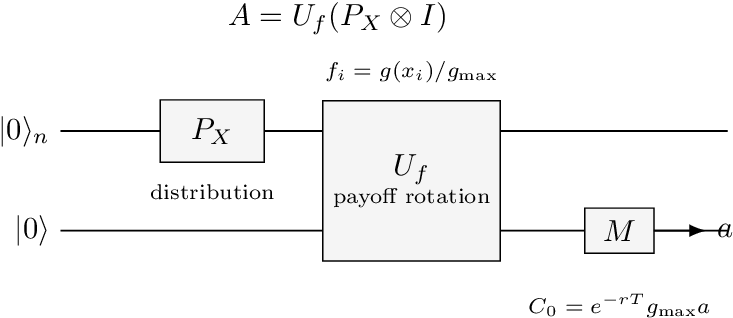
The circuits below follow the gate-level decomposition of Stamatopoulos et al. and are meant to make the oracle structure explicit. Our implementation uses Qiskit Finance’s log-normal distribution loader and LinearAmplitudeFunction to produce the same normalized piecewise-linear payoff rotation [13]. Thus the code and the figures implement the same pricing map, although our code delegates the low-level comparator and rotation to Qiskit rather than the gates shown here.
Stamatopoulos et al. implement in two stages [7]. A reversible comparator determines whether the encoded price index exceeds the strike. Let be the th bit of the strike in binary. The comparator acts on the price register , carry ancillas , and a comparator qubit , setting when . The construction uses only CNOT and Toffoli gates, similar to the half-adder.
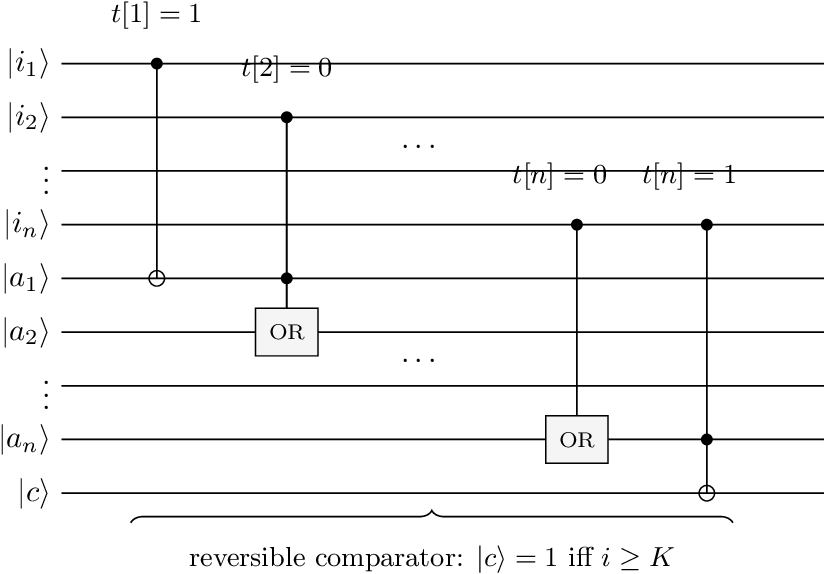
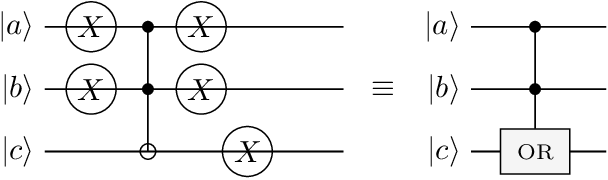
The OR gate in Fig. 5 decomposes into Pauli- gates and a Toffoli, as shown in Fig. 6: negate the inputs, apply a Toffoli (which computes AND), negate the output and restore the inputs. The result is with and unchanged.
Second, once stores the comparison result, a controlled rotation loads the payoff into a fresh ancilla qubit. The rotation is applied only on the in-the-money branch (). Following Stamatopoulos et al., the rotation angle on that branch is , where
is a scaling parameter that controls the approximation quality, and is the largest grid index. The key step is the expansion around :
For small , the objective-qubit probability is therefore affine in the payoff (a linear transformation of the option payoff plus a small constant). This linearity is what allows Eq. [eq:amplitude-expectation] to hold as a pricing identity after the known shift and scale are removed.
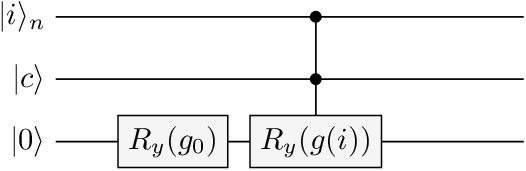
The Asian case uses the components at a greater cost. Instead of loading a single terminal price, the circuit must prepare correlated monitoring-date prices, compute their arithmetic average into a work register using reversible adders, apply the comparator and payoff rotation to the average, and then uncompute the work registers so that in Eq. [eq:grover-iterate] returns the ancillas to a clean state. Every Grover query therefore contains path loading, reversible averaging, comparison with the strike, payoff rotation, and the corresponding inverse operations. This overhead is the circuit cost of path dependence, and it is why path-dependent options are often used to motivate quantum advantage in derivative pricing [7, 8]. There is a hitch, variance reduction, optimized integrators, and better sampling can make the practical gap much smaller than a simple-Monte-Carlo comparison suggests.
Results and discussion
Classical benchmark
The European call is mainly a check on the simulation pipeline. Simple Monte Carlo converges to the Black—Scholes price with the expected rate from Eq. [eq:mc-se]. With paths, averaged over independent trials, the mean standard error is and the mean absolute error is . This result is not computationally interesting by itself because the European call has a closed form.
The Asian option is the relevant classical benchmark. Fig. 2 shows that the Kemna—Vorst control variate preserves the Monte Carlo exponent but changes the prefactor sharply. At paths, the standard error falls from for simple Monte Carlo to with the control variate. This is a standard-error reduction of and a variance reduction of , consistent with the high correlation between arithmetic and geometric Asian payoffs used by Kemna and Vorst [4, 5].
Check Reference value Our estimate Diagnostic
Geometric Asian Xu days Xu days Xu days
: Benchmark checks for the Asian-pricing code. Xu—Zhang—Wang values are from Table 4, row “w/o ALL”, their plain Black—Scholes Monte Carlo ablation [11].
These checks have a narrow purpose. They verify the simulation and control-variate implementation. They do not speak to the legitimacy of the market model as a predictor. For the Xu—Zhang—Wang rows, the diagnostic uses the Monte Carlo standard error reported in their table. The -day check is the loosest row, but it remains inside the three-standard-error band. The quantum method is therefore being measured against a validated variance-reduced baseline, not only against simple Monte Carlo.
European quantum validation
The European call has a closed form, which makes it useful as a calibration problem. The statevector calculation removes sampling noise and IAE uncertainty, so the test isolates the pricing map in Eqs. [eq:distribution-loading]—[eq:amplitude-expectation]. If the state preparation and payoff rotation are correct, the objective-qubit probability should reproduce the Black—Scholes price after the known rescaling in Eq. [eq:european-amplitude-price].
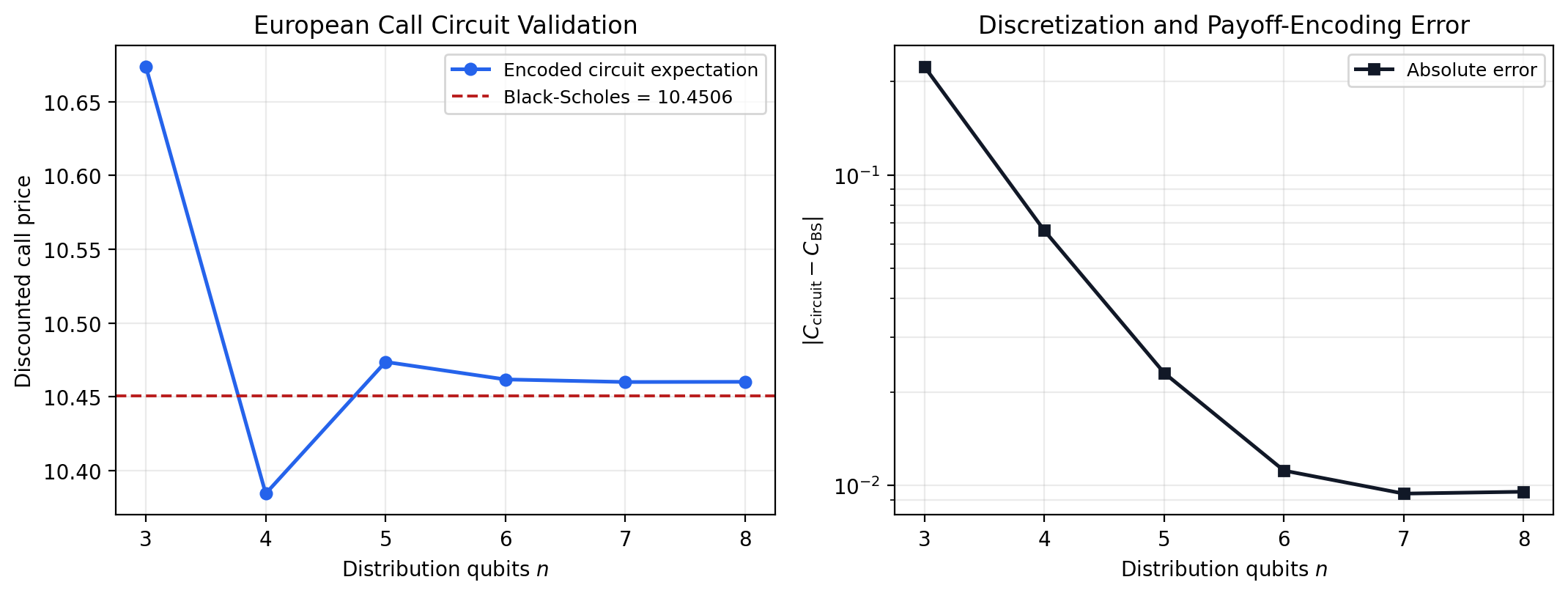
The encoded price is already close with a small register. At distribution qubits the circuit gives , an absolute error of against the Black—Scholes price . At the error falls to . It then plateaus near , with errors and at and . It seems like refining the price grid helps up to a limit.
IAE estimates the amplitude already present in the circuit [12]. It does not remove truncation error in the log-normal grid, nor does it repair the first-order payoff rotation used in the Stamatopoulos construction [7]. The statevector result therefore validates the circuit as an amplitude-encoding implementation, but not as a hardware speedup.
Resource tradeoff
The query speedup from QAE is meaningful only after the cost of one query is fixed. Table 2 reports the compiled size of the European operator. One Grover iterate contains , , and two reflections, so an IAE run repeats a circuit at least of this scale many times. The counts are generated by scripts/generate_quantum_results.py –quick with Qiskit 2.3.1, Qiskit Finance 0.4.1, and Qiskit Algorithms 0.4.0, transpiled to the cx,u basis at optimization level . Grinko et al. reduce the estimation overhead by avoiding QPE, but the state-preparation and payoff oracles remain the dominant problem-specific cost [12].
Distribution qubits Grid points Total qubits Depth CX gates
$3$ $8$ $7$ $143$ $94$
$4$ $16$ $9$ $218$ $141$
$5$ $32$ $11$ $303$ $196$
$6$ $64$ $13$ $426$ $267$
$7$ $128$ $15$ $607$ $370$
$8$ $256$ $17$ $922$ $537$: Transpiled European-call -operator resources. Counts are for state preparation and payoff loading only.
Monitoring dates Grid paths Total qubits Depth CX gates
$2$ $16$ $5$ $293$ $194$
$3$ $64$ $7$ $2396$ $1963$: Toy arithmetic-Asian oracle checks. Each monitoring date uses a two-qubit shock grid. These circuits validate the finite-grid payoff map; they are not production resource estimates.
The growth is moderate for the European call because the payoff depends only on , unlike the Asian circuit. Table 3 shows the same payoff map on small finite grids. The three-date circuit reproduces its exact grid price to numerical precision, but it already reaches depth before amplitude estimation. A linear extrapolation from three dates to dates would give depth on the order of and about CX gates before any Grover repetitions. This estimate is only a scale check. Exact finite-grid loading would grow faster, while a serious production oracle would need more structure than the toy circuit uses to compensate for market complicated market dynamics.
For the daily Asian option used in the classical benchmark, a quantum oracle would need to load correlated prices, compute the arithmetic average reversibly, compare it with the strike, rotate the payoff qubit, and uncompute the work registers. Stamatopoulos et al. identify this path-dependent structure as the place where reducing the number of samples could matter most [7]. Wang and Kan reach a similar conclusion under stochastic volatility, where the resource analysis is dominated by arithmetic and path simulation circuits rather than by the abstract QAE primitive [8].
These counts are still noiseless circuit counts. Stamatopoulos et al. ran only small European-call instances on IBM hardware and needed error mitigation to reduce two-qubit gate errors [7]. IAE removes the QFT register and deep controlled powers, but it still requires repeated coherent applications of the Grover algorithm [12]. For larger path-dependent contracts, the relevant hardware question is therefore not only the number of oracle calls, but whether the full oracle can be executed with enough fidelity. This is why fault-tolerant resource estimates, such as the -count and -depth analysis in Wang and Kan, are more informative than query counts alone [8].
Conclusion
We studied option pricing with QAE against a variance-reduced classical baseline. For the European call, the statevector calculation verifies the amplitude map used in the previous section. After loading the log-normal terminal distribution and encoding the payoff into the objective qubit, the recovered price approaches the Black—Scholes value as the grid is refined. The remaining error likely comes from grid truncation and payoff encoding.
The Asian option gives the more useful test. With daily monitoring, the Kemna—Vorst control variate lowers the variance of the arithmetic Asian estimator by at paths. This changes the baseline by three orders of magnitude in variance. On the quantum side, each Asian oracle must prepare the path distribution, compute the average reversibly, compare with the strike, load the payoff, and uncompute the work registers before the Grover iterate can be applied. The “quantum advantage” depends on the payoff, the available variance reduction, and the cost of implementing the oracle. It also depends on hardware. A deep oracle repeated inside amplitude estimation is sensitive to noise on present devices and expensive under error correction. For the Black—Scholes Asian case considered here, the evidence points in one direction. The query speedup is real, but it is not the bottleneck. The bottleneck is the full path-dependent oracle, measured against a control variate that already removes most of the classical variance.
[1] P. Rebentrost, B. Gupt, and T. R. Bromley, “Quantum computational finance: Monte Carlo pricing of financial derivatives,” Physical Review A, 98, no. 2, 022321 (2018), doi:10.1103/PhysRevA.98.022321, https://link.aps.org/doi/10.1103/PhysRevA.98.022321.
[2] F. Black and M. Scholes, “The pricing of options and corporate liabilities,” Journal of Political Economy, 81, no. 3, 637—654 (1973), doi:10.1086/260062.
[3] R. C. Merton, “Theory of rational option pricing,” The Bell Journal of Economics and Management Science, 4, no. 1, 141—183 (1973), doi:10.2307/3003143.
[4] P. Glasserman, Monte carlo methods in financial engineering, (2004), doi:10.1007/978-0-387-21617-1.
[5] A. G. Z. Kemna and A. C. F. Vorst, “A pricing method for options based on average asset values,” Journal of Banking & Finance, 14, no. 1, 113—129 (1990), doi:10.1016/0378-4266(90)90039-5, https://linkinghub.elsevier.com/retrieve/pii/0378426690900395.
[6] G. Brassard, P. Hoyer, M. Mosca, and A. Tapp, “Quantum amplitude amplification and estimation,” Contemporary Mathematics, 305, 53—74 (2002), doi:10.1090/conm/305/05215.
[7] N. Stamatopoulos, D. J. Egger, Y. Sun, C. Zoufal, R. Iten, N. Shen, and S. Woerner, “Option Pricing using Quantum Computers,” Quantum, 4, 291 (2020), doi:10.22331/q-2020-07-06-291, http://arxiv.org/abs/1905.02666.
[8] G. Wang and A. Kan, “Option pricing under stochastic volatility on a quantum computer,” Quantum, 8, 1504 (2024), doi:10.22331/q-2024-10-23-1504, http://arxiv.org/abs/2312.15871.
[9] A. Manzano, G. Ferro, Á. Leitao, C. Vázquez, and A. Gómez, “Alternative pipeline for option pricing using quantum computers,” EPJ Quantum Technology, 12, no. 1, 28 (2025), doi:10.1140/epjqt/s40507-025-00328-3, https://epjquantumtechnology.springeropen.com/articles/10.1140/epjqt/s40507-025-00328-3.
[10] G. Rendon, R. Kshirsagar, and Q. H. Tran, Exponential Improvement on Asian Option Pricing Through Quantum Preconditioning Methods, (2025), doi:10.48550/arXiv.2501.15614, http://arxiv.org/abs/2501.15614.
[11] L. Xu, H. Zhang, and F. L. Wang, “Pricing of Arithmetic Average Asian Option by Combining Variance Reduction and Quasi-Monte Carlo Method,” Mathematics, 11, no. 3, 594 (2023), doi:10.3390/math11030594, https://www.mdpi.com/2227-7390/11/3/594.
[12] D. Grinko, J. Gacon, C. Zoufal, and S. Woerner, “Iterative quantum amplitude estimation,” npj Quantum Information, 7, no. 1, 52 (2021), doi:10.1038/s41534-021-00379-1, https://www.nature.com/articles/s41534-021-00379-1.
[13] Qiskit Finance Development Team, Qiskit finance, (2024), https://github.com/qiskit-community/qiskit-finance.